I agree with David.
The strings are nearly always hidden in mapping paths or usage guides etc. I think that the RD is a better approach. The allowable string values are documented and agreed and stored in one place – the RDL. After all, we have been advocating the approach in PLCS since the beginning.
(BTW – this email contains diagrams – if anyone does not receive the diagrams please let us know as I am not sure if I am using too much Microsoft specific stuff to create the email)
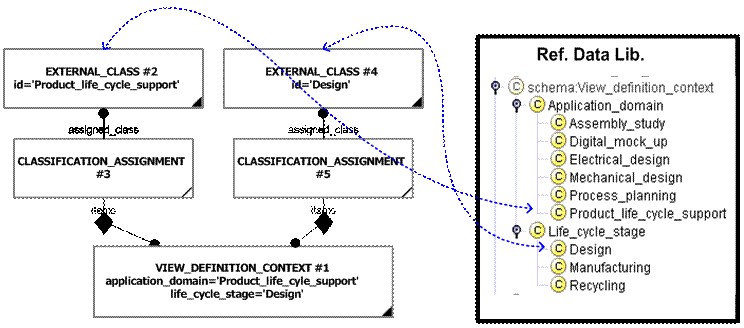
I would advocate using both strings and classification as shown in the diagram below
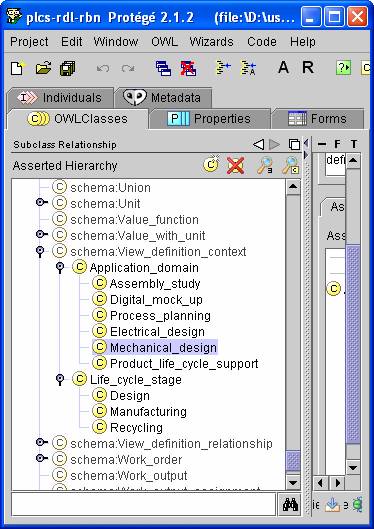
You can deduce which classification is the application_domain and which is the life_cycle stage by looking at the super classes in the reference data.
The only rule is that the entity string values should be the same as the class names.
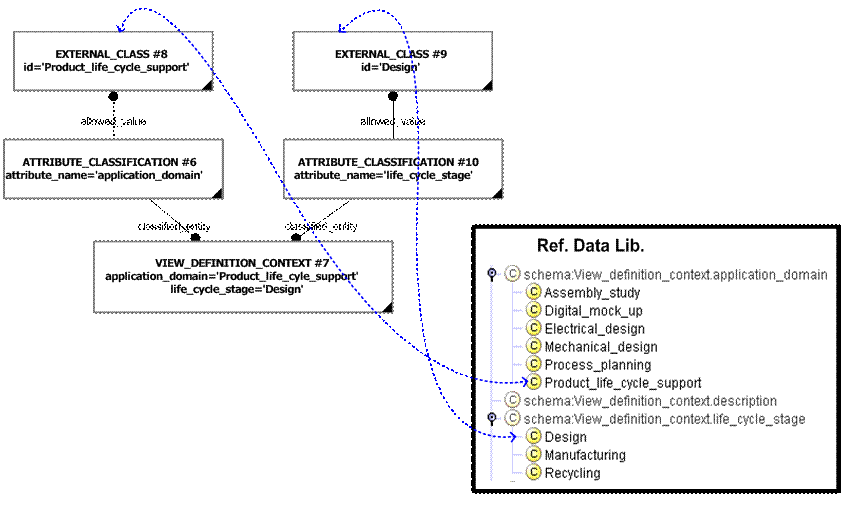
We do have the option to use attribute classification as shown in the diagram below. However, I am not sure what benefit this brings as we can achieve exactly the same affect using classification assignment as described above. Hence we agreed a while back that we would avoid using attribute classcifcation – this is documented in Capability (C010): assigning_reference_data
Regards
Rob
-------------------------------------------
Rob Bodington
Eurostep Limited
Web Page: http://www.eurostep.com http://www.share-a-space.com
Email: Rob.Bodington@eurostep.com
Phone: +44 (0)1454 270030
Mobile: +44 (0)7796 176 401
-----Original Message-----
From: David
Price [mailto:david.price@eurostep.com]
Sent: 11 August 2004 21:36
To: plcs-dex@lists.oasis-open.org
Subject: RE: [plcs-dex]
Classification of View_definition_context
All,
I’d say one benefit to the RD approach is that users can debate and agree on domain and life cycle stage and then, most importantly, easily *share* that agreement. Attribute value constraints could well be hidden in text or EXPRESS rules or not agreed at all if RD isn’t used. Even if pilots decide agree to use the attribute values for some reason (e.g. they only ever use one domain and life cycle stage), publishing the RD as the source of the standard values is still useful.
Cheers,
David
-----Original Message-----
From: tim turner
[mailto:timturner11@bellsouth.net]
Sent: 11 August 2004 21:18
To: 'Rob Bodington';
plcs-dex@lists.oasis-open.org
Subject: RE: [plcs-dex]
Classification of View_definition_context
The strings are just listing the possible exchange values. The RDL route does the same but allows the list of possibles to expand...
However, that aside, and assuming the RDL route, your example would then become either;
#230=VIEW_DEFINITION_CONTEXT('application_domain', 'life_cycle_stage', 'part definition'); #231=CLASSIFICATION_ASSIGNMENT(#232, (#230), '');#232=EXTERNAL_CLASS($, 'product life cycle support', $, $); #233=CLASSIFICATION_ASSIGNMENT(#234, (#230), '');#234=EXTERNAL_CLASS($, 'design', $, $); OR; #230=VIEW_DEFINITION_CONTEXT('', '', 'part definition'); #231=CLASSIFICATION_ASSIGNMENT(#232, (#230), '');#232=EXTERNAL_CLASS($, 'product life cycle support', $, $); #233=CLASSIFICATION_ASSIGNMENT(#234, (#230), '');#234=EXTERNAL_CLASS($, 'design', $, $); I don't really see the benefit of one over the other (or in expanding from 1 instance to 5 for that matter!).The former just documents the attribute name (class) which we already know from the model & is therefore, arguablyredundant. Neither case dictates any order in which the assignments should be read in terms of the attributes of #230, other than their position in the file, so to remove any ambiguity we probably have to use another mechanism. Although not ideal (semantically), Identification_assignment could be used as in the following .. #230=VIEW_DEFINITION_CONTEXT('', '', 'part definition');#231=IDENTIFICATION_ASSIGNMENT('application_domain', '', $, (#230));#232=CLASSIFICATION_ASSIGNMENT(#233, (#231), '');#233=EXTERNAL_CLASS($, 'product life cycle support', $, $); #234=IDENTIFICATION_ASSIGNMENT('life_cycle_stage', '', $, (#230));#235=CLASSIFICATION_ASSIGNMENT(#236, (#234), '');#236=EXTERNAL_CLASS($, 'design', $, $); However, maybe there's a property or attribute classification that's better suited to this. I can't comment on the pilot's usage, so I'll leave that to others. kind regards,Tim -----Original Message-----
From: Rob Bodington [mailto:rob.bodington@eurostep.com]
Sent: 11 August 2004 12:38
To: plcs-dex@lists.oasis-open.org
Subject: [plcs-dex] Classification of View_definition_contextHi
I have had a look at Capability (C002):— representing_parts
It talks about View_definition_context
However it implies that we should use strings for specifying the application_domain and life_cycle stage.
E.g.
#230=VIEW_DEFINITION_CONTEXT('product life cycle support', 'design', 'part definition');I think that it would be better to use reference data. In other words create OWL sub classes of View_definition_context – one for Application_domain and one for Life_cycle_stage as shown in the screenshot below.I have also included the classes from AP214 and the PDM Schema. Apart from the obvious one (Product_life_cycle_support)In the various pilots – what values have people used for these attributes?Can we standardize on them?It also raises a wider question. Where we have an EXPRESS entity which has a mandatory string attribute, e.g.ENTITY View_definition_context;
application_domain : STRING;
life_cycle_stage : STRING;
description : OPTIONAL STRING;
END_ENTITY;And we use reference data. What String value should we use?Should we set it to ‘’ or perhaps the name of the class?If we use the name of the class AND classification then we will be compatible with other STEP parts (albeit at an ARM level)
Regards
Rob-------------------------------------------
Rob Bodington
Eurostep Limited
Web Page: http://www.eurostep.com http://www.share-a-space.com
Email: Rob.Bodington@eurostep.com
Phone: +44 (0)1454 270030
Mobile: +44 (0)7796 176 401