|
Rich, I think I am closer to understanding your use case, but
I still believe there are architectural solutions that can be implemented using
current features of the 3.0 specs.
See attached
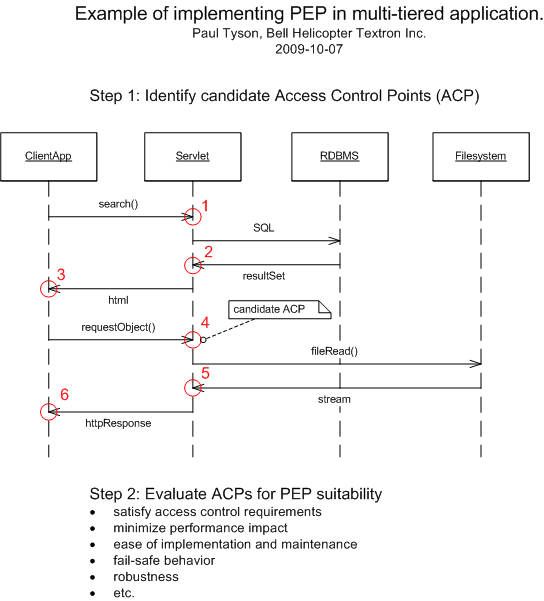
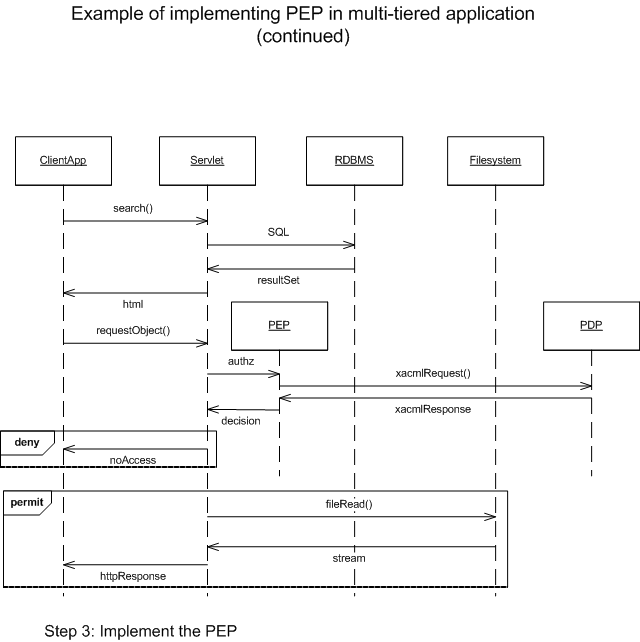
diagrams, which I put together to show the process of implementing a PEP in a
multi-tiered application. You have a requirement:
(1) "Authorization
is determined prior to accessing any resources at all."
Therefore the only
choice for a PEP is at the access control point (ACP) labeled "1" in the
diagram, "base-system-no-authz.png". At this point, all the system
has is search parameters from the user. With your URI-reference scheme,
you are proposing that the PEP compose a series of URIs representing an XML
document that might be created at a future point in the process (perhaps,
after ACP 2). But how could it compose these URIs without knowledge
of what was in the database? Why couldn't it issue a
request to the PDP, "Can Jones query the database", and get the decision (with
obligation) like "yes, but only for books not by Jones, or costing less than 50
dollars"?
I'm probably still
missing something about your use case and architectural
constraints.
Regards,
--Paul
Hi Paul,
Thanks for the comments. I don't significantly
disagree with any of the specific points you mentioned, however, in your point
3, which, if I read it correctly was addressing my point 1, I don't think your
example directly addresses the point I was making, which is the following:
- The URI scheme does not require access to either the document or the
database. Authorization is determined prior to accessing any resources at
all.
The XPath scheme requires access to the actual document, or issuing
the query to the database, as you indicated in your alternative suggestion:
"Query
book database for candidate records".
The URI scheme would
base the decision on the query alone, before it is executed. The policies
would scope based on policy-specified URI w scope. The request URI would be
evaluated based on whether it fell within the hierarchical scope of the
policy-specified URIs. (all URIs in policy evaluation would be in the form
described in the proposal)
To me, this is a significant
distinction. The reason it is required in XPath is that the namespaces need to
be resolved. With the URI scheme, the namespaces can be resolved with only the
schema of the target resource, the actual resource does not need to be
accessed. i.e. the risk that is avoided is having an unnecessary access of the
resource prior to determination of authorization.
Thanks,
Rich
Tyson, Paul H wrote:
3898C40CCD069D4F91FCD69C9EFBF09603E1143B@txamashur004.ent.textron.com
type="cite">
I still can find no compelling reason to
introduce this into the standard. Any enterprise could certainly adopt
this system of resource identification without violating the XACML
specification. I cannot see any advantage in doing this, but I
believe Rich when he says there may be highly constrained situations that
force one to this type of solution. That is not a good enough reason
to put it in the standard, though.
To address some specific
points:
1. XPath performance overhead. I
don't know what others have experienced, but I have used saxon xslt engine
for years, and simply cannot slow it down no matter how complex my xpath
expressions are, or how large the input documents are. I don't know
what xpath engines are commonly used in XACML implementations, but poor
performance is not an inherent feature of xpath processing. In the
case of multiple authorization decisions on a single document, it would be a
very naive implementation that actually re-parsed the document for
every decision.
2. Paradigm shifting:
Attribute(Designator|Selector), xpath vs. regex. Really, who *likes*
regex? ;-) XACML is an XML application, therefore the first and favored
approach should be xpath. It's nice to be able to use regex when
necessary, but I have never seen a case where it is the best first choice in
XML processing (except for datatyping and value checking, but those areas
are outside the domain of xpath). A developer who knows regex
better than xpath would want to use regex first, but xpath is a much
more natural fit with XML.
3. Not wanting to expose entire XML
document to PDP. If this is a hard constraint, there
are other architectural alternatives. Take the book catalog use
case. For my money, I would do something like this before using the
alternative URI representation:
a. Query book database for candidate
records
b. Send multi-decision request with
attributes like ((user=Jones), (type=book, author=Jones, price=50),
(type=book,author=Smith,price=30), ...)
c. Receive
results
d. Form XML for delivery to user,
based on results.
This model would work for all cases where
the XML is manufactured from database or other backend sources. Just
move the authorization step ahead of the XML creation.
The book use case does not actually depend
on any hierarchical relations for the decision, so it is not the best
example.
Regards,
--Paul
Based on Oct 8 TC meeting,
proposals were solicited to address both issue 11, and the broader issue
of whether or not we should consider separating out the XML document parts
of Hier, Mult to another profile.
The attached document represents
a proposed addition to Hier profile to address issue 11 (it is the same as
attachment to http://lists.oasis-open.org/archives/xacml/200909/msg00076.html,
except w highlight changes turned off to make Hier sections 2.2, 2.2.1
easier to read). (It is also included as attachment to emphasize it is a
proposal, as opposed to a draft of an agreed change, which would be rev'd
in the repository)
The following comments state why I think the
proposed addition to Hier is needed (#1, #2) and why I think the
hierarchical properties of XML documents should remain in the Hier/Mult
profiles (#3), and that if other profiles are developed for XML docs then
those profiles should refer to Hier/Mult for their hierarchical access
properties.
- The proposed addition to Hier is needed because it represents
functionality that is currently missing from the Hier profile that
enables identifying resources within an XML document without having to
provide the XML document itself.
- The problem introduced by requiring the presence of the XML
document is that, for example, it requires actually accessing and
exposing the protected resources in order to determine if access is
allowed to those same resources. While this may be an acceptable
increase in risk of exposure in some application environments, it may
not be acceptable in others where very sensitive data is involved, and
an alternative should be provided for those cases.
- For more specific example, XML-frontended datastores contain
resources in relational or other legacy storage mechanisms and
primarily use XML as vehicle for containing and carrying those
resources. Requiring construction of XML documents containing those
resources, which could potentially contain very sensitive data, in
order to construct a request to determine whether access to those
resources is allowed should not be required if alternative mechanisms
which do not require this exposure are readily
available.
- The proposed addition is also needed to provide a unique uniform
naming mechanism and policy reference mechanism for all hierarchical
resources whether they are contained in an XML document structure or
some other hierarchical structure. i.e. XML documents have an inherently
simple hierarchical structure that has an implicit resolved name
structure in the underlying XPath data model that should be able to be
used for resource identification and policy definition despite the fact
that the XPath language, itself, does not expose this capability of the
underlying reference model.
- The attached proposal uses a commonly used mechanism (Clark
notation: curly braces around resolved namespace prefix) that
addresses the omission from the XPath language of the ability to
enable single string display representation of explicit full
hierarchical path to each node. This path is also percent-encoded
where required in order that it can be used as a URI fragment as
described in section 2.2.1 of attachment, which seamlessly augments
the existing Hier URI scheme in section 2.2.
- It is recommended to leave the XML document sections in Hier/Mult
for the following basic reason: The introduction to the Hier profile
(section 1, lines 41-54) makes it clear that XML documents are regarded
as generally only one possible "representation" of the actual target
hierarchical resources. Therefore there seems to be little to be gained
by separating out one representation of the general hierarchical
resources covered by the profile into a separate profile. What would
seem to make more sense is that a more general XML/WebServices profile
could reference the Hier profile when necessary for matters concerning
the "hierarchical" access control aspects of the more general
XML/WebServices problem space addressed by that new profile.
Additional context for this proposal has already been discussed
in tc emails and will not be repeated here, but may be found in the
following references to those emails:
Comments and suggestions welcome.
Thanks,
Rich
|
{kind=link}
{kind=link}