[Date Prev] | [Thread Prev] | [Thread Next] | [Date Next] -- [Date Index] | [Thread Index] | [List Home]
Subject: Re: [dita-lightweight-dita] Groups - Draft DTDs for lightweight DITA (without HTML5 specializations) uploaded
|
Thank you for this updated version. I was able to view the samples
fine. Of course, the next step was to start stressing the options a
bit more. Attached is a more fully developed test.dita in which I
worked with the object element and associated processing to produce
HTML5 video out. I found that for the particular video notation I was trying to support, I needed to add the type attribute back into param. It is necessary to convey the mime type of the reference object to pass into the corresponding source element in HTML5. I discovered that I could not infer the mimetype from the resource's extension alone. For example, an extension of ".avi" might be one of several mime type including video/mp4 and video/mspm4. There may be other solutions; this was just the most obvious hack for now (see the corresponding code in test.dita). <!-- DRD: @type added to enable full video parm description--> <!ATTLIST param name CDATA #REQUIRED value CDATA #IMPLIED type CDATA #IMPLIED class CDATA "- topic/param "> Also, I tried to label the examples as semantic DITA <example> sections, but quickly learned that this markup is excluded. OK, I get the rationale for setting up equivalences between XDITA and HDITA, but in this case, I decided that I was truly missing a semantic intent that would have made my DITA content more intelligent than the corresponding HTML it needed to go into. My takeaway is that "Coding equivalence alone is not a reason to restrict meaningful DITA semantics from a content model." I know that this assertion opens the door to unconstrained scope creep. But it is probably the defining difference between the necessary architectural limitations of lw-dita and of "regular DITA used sensibly for the Web." Another limitation is that I was still unable to convert my existing simple topics with "blog-equivalent prolog metadata" into lw-dita samples due to the still constrained prolog element. Here, I still get more selection utility similar to what a WordPress or Drupal author might have by using "DITA used simply." I don't want to cause scope creep at all; I think Lightweight DITA serves useful function for some direct use cases will that marshall neatly into the other DITA content in the defined scenario evaluations. But I'm still missing the opportunity to message to the Web community (not an existing DITA community) about what I can do with this content that is superior to their directly-coded HTML5. This is why I'm still entertaining the alternate thought of a usage profile (perhaps defined by Schematron-like bounding assertions) for using regular DITA in a manner that constrains it to valid direct use on the Web but still offers access to all of the "intelligent content" features that enable creation of rich, adaptive, personalized, selectable content for the Web. I don't think the two ideas are at odds; "DITA used simply" is just about "avoid this" conventions on an existing system. By the next meeting I will have updated my public Jotsom library of lw-dita materials that includes live rendition of these attached topics. -- Don On 11/4/2014 11:33 AM, Michael
Priestley wrote:
|
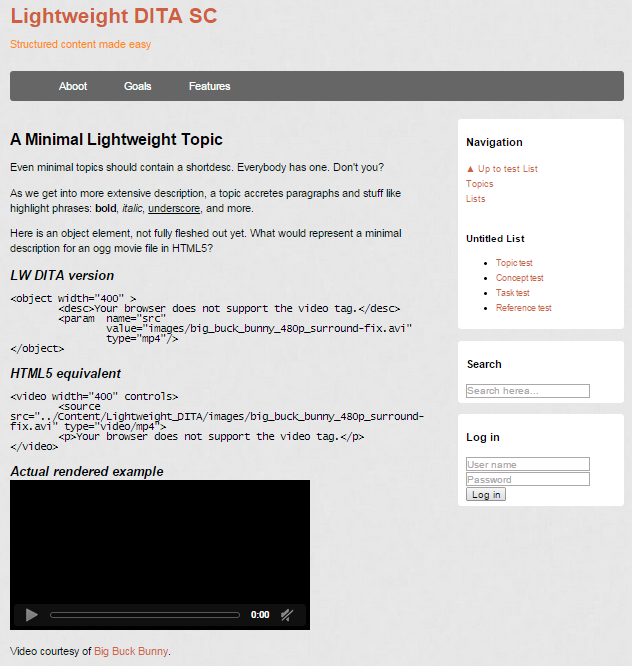
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE topic PUBLIC "-//OASIS//DTD LW DITA Topic//EN" "topic.dtd"> <topic id="abc123"> <title>A Minimal Lightweight Topic</title> <shortdesc>Even minimal topics should contain a shortdesc. Everybody has one. Don't you?</shortdesc> <body> <p>As we get into more extensive description, a topic accretes paragraphs and stuff like highlight phrases: <b>bold</b>, <i>italic</i>, <u>underscore</u>, and more.</p> <p>Here is an object element, not fully fleshed out yet. What would represent a minimal description for an ogg movie file in HTML5?</p> <section> <title>LW DITA version</title> <pre> <object width="400" > <desc>Your browser does not support the video tag.</desc> <param name="src" value="images/big_buck_bunny_480p_surround-fix.avi" type="mp4"/> </object> </pre> </section> <section> <title>HTML5 equivalent</title> <pre> <video width="400" controls> <source src="../Content/Lightweight_DITA/images/big_buck_bunny_480p_surround-fix.avi" type="video/mp4"> <p>Your browser does not support the video tag.</p> </video> </pre> </section> <section> <title>Actual rendered example</title> <object width="400" > <desc>Your browser does not support the video tag.</desc> <param name="src" value="images/big_buck_bunny_480p_surround-fix.avi" type="video/mp4"/> </object> <p> Video courtesy of <xref scope="external" href="http://www.bigbuckbunny.org/";>Big Buck Bunny</xref>. </p> </section> </body> </topic>
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE topic PUBLIC "-//OASIS//DTD LW DITA Topic//EN" "topic.dtd">
<topic id="zz__WCYSKR">
<title>Overview of <i>Lightweight DITA</i> (XDITA and HDITA)</title>
<shortdesc>Required shortdesc.</shortdesc>
<!--
<prolog>
<author type="creator">Michael Priestley</author>
<critdates>
<created date="2014-04-02"></created>
</critdates>
<metadata>
<category></category>
<othermeta name="featureImage" content="Generic 206 px.png"/>
<othermeta name="status" content="draft"/>
</metadata>
</prolog>
-->
<body>
<!--
<note>These values are now in metadata in a standard topic:
<ul>
<li><p>First draft: April 2, 2014</p></li>
<li><p>Author: Michael Priestley</p></li>
</ul>
</note>
-->
<p>Audience: People who are already familiar with DITA â?? this is not an introduction to DITA, although the full spec should definitely serve that purpose.</p>
<p>The goal of this proposal is to align a lightweight DITA profile in XML with an equivalent markup specification based on HTML5.</p>
<p>While XML-based publishing chains remain the industry standard for many content-centric industries (such as publishing, pharmaceutical, and aerospace), concerns have been raised about their complexity, especially as a barrier to new adopters or contributing authors.</p>
<p>Many of the responses fall into one of two categories:</p>
<ol>
<li><p>Simplify the XML model, as seen with many of the lightweight DITA tools that have come to market over the last few years</p></li>
<li><p>Rebase on an HTML5 model, as seen with O'Reilly and more recently Pearson</p></li>
</ol>
<p>The challenge with the lightweight DITA approach is that historically it has not been standardized, so each implementation introduces a slightly different flavor of lightweight DITA; in addition, there are some adopters who are reluctant to accept any solution that uses XML in any way, simply because of the requirement to do at least one transform step as part of the publishing process.</p>
<p>The challenges with the HTML5-based approach are again based on a lack of standardization: each new extension of HTML5 introduces its own additional semantics and constraints, locking the content into a particular tool or vendor pipeline. The additional semantics and constraints also may require a custom authoring environment, resulting in another barrier to content portability, without the advantages of authoring-time validation that an XML-based approach provides. Finally, even though the approach may eliminate processing steps for the case of simple content, more complex content scenarios â?? such as content reuse and filtering, or indexing and link redirection â?? require additional processing steps that reintroduce the complexity of an XML-based approach, without the advantage of existing standards-based solutions.</p>
<p>This proposal suggests a third way â?? defining both a lightweight XML model based on DITA that can be used for validated authoring and complex publishing chains, and a lightweight HTML5 model that can be used for either authoring or display.</p>
<p>The two schemes â?? provisionally named XDITA and HDITA - are designed for full compatibility with each other as well as conformance with the OASIS DITA and W3C HTML5 standards. They give HTML5 users a set of standardized mechanisms to access the power and flexibility of DITA's reuse and specialization capabilities, and give DITA users a way to integrate and interact with HTML5-based content systems without complex mapping or cleanup steps.</p>
<p>The key areas for alignment are as follows:</p>
<ol>
<li><p>Structural elements â?? paragraphs, lists, etc.</p></li>
<li><p>Specialized sections</p></li>
<li><p>Inline markup â?? highlighting, links, etc.</p></li>
<li><p>Tables</p></li>
<li><p>Images and multimedia</p></li>
<li><p>Navigation/Maps</p></li>
<li><p>Attributes (including ARIA)</p></li>
</ol>
</body>
</topic>Attachment:
LightweightDITA_01.png
Description: PNG image
[Date Prev] | [Thread Prev] | [Thread Next] | [Date Next] -- [Date Index] | [Thread Index] | [List Home]
{kind=link}