[Date Prev] | [Thread Prev] | [Thread Next] | [Date Next] -- [Date Index] | [Thread Index] | [List Home]
Subject: LRR: identifiers for divisions of a court
A release of the MLZ reference manager that uses the LRR identifiers
went out a few days ago, and there has been some feedback from users.
One item of interest is the need to specify divisions of a court
within the identifier:
https://forums.zotero.org/discussion/46508?page=1#Item_4
This seems a good time for an informal explanation of the structure of
the LRR identifiers.
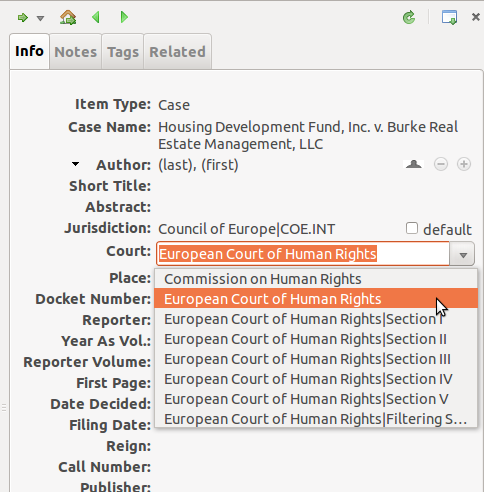
(The use of the identifiers in the MLZ user interface is shown in the
attached screenshot.)
## Description
Here is the identifier for Section I of the European Court of Human
Rights under the Council of Europe:
coe.int;echr~section.1
Identifiers are expressed as lower-case ASCII 128 letters, numbers,
periods, colons, semicolons, and tilde characters. Other characters
are not permitted.
As shown in the example above, an LRR identifier consists of at most
three elements: a Jurisdiction specifier; a semicolon-separated Court
specifier; and a tilde-separated Court Division specifier.
(1) Jurisdiction specifier (coe.int)
A jurisdiction specifier is a colon-delimited list of one or more
elements, beginning with the element having the largest scope. The
first element may be the ISO 3166 code for a top-level national
jurisdiction, or an arbitrary code identifying a non-national scope
ending in ".int". Sub-elements following the top-level are not an
expression of judicial or administrative hierarchy. At the technical
level, their only role is to prevent namespace conflicts among
entities that share the same Court specifier. The subelements should,
however, loosely reflect the organization of institutions within the
national jurisdiction, as they will be used to generate menus,
information pages, and the like.
(2) Court specifier (echr)
A court specifier follows the Jurisdiction specifier, and is separated
from it by a semicolon. The court specifier should be derived from the
name of target institution, either as a set of initials (where these
are widely recognized) or as a roman transliteration of the name in
its original language. It identifies an institution with
decision-making authority. In jurisdictions that recognize multiple
official languages, the English form is preferred as the base language
for deriving the identifier. This is not a reflection of priority or
relative authority; it is simply a matter of technical convenience.
(3) Court Division specifier (section.1)
A Court Division specifier follows the Court specifier, and is
separated from it by a tilde. The court division specifier is derived
in the same way as the Court specifier. Where roman numerals are used
in the human-readable name, arabic numerals should be used.
## Differences from URN:LEX
While the LRR identifiers resemble the URN:LEX scheme, there are
significant differences, driven by the differing objectives of the two
systems. The URL:LEX schema is here:
https://datatracker.ietf.org/doc/draft-spinosa-urn-lex/?include_text=1
URL:LEX seeks to give semantic expression to the structure of
authority within target jurisdictions, and objective closely tied to
the requirement that identifiers be settled by national authority
(schema 5.2). To permit lightweight assignment of identifiers for
referencing convenience, the LRR abandons the strict alignment of
identifier structure with the hierarchy of authority. One consequence
of the difference is that an LRR identifier need not change when the
status of a sub-jurisdiction changes. For example, the code for
Hawai'i in the United States would be "us:hi" both before and after
statehood.
In the structure of identifiers, the LRR draws a distinction between
scope of jurisdiction (the first specifier) and the lawmaking body
(the second specifier). This does not appear to be the case in URN:LEX
(schema 4.4). The distinction is important in the LRR, because the two
must be stored to separate fields in descriptive citation data.
To avoid confusion between the two schemes, the LRR adopts ".int"
rather than ".lex" as the suffix for non-national scopes (see schema
2.4).
Finally, the LRR uses the tilde separator to specify the division of a
law-issuing body, so that it can be parsed out and stored in
descriptive citation data. As far as I can tell, the current draft of
URN:LEX does not provide a means of encoding this information.
Frank
Attachment:
echr.png
Description: PNG image
[Date Prev] | [Thread Prev] | [Thread Next] | [Date Next] -- [Date Index] | [Thread Index] | [List Home]
{kind=link}