[Date Prev] | [Thread Prev] | [Thread Next] | [Date Next] -- [Date Index] | [Thread Index] | [List Home]
Subject: FW: [legalcitem] Prolegomena to the constitution of subcommittees
|
Dear all, Here are some comments in red (email in Rich Text format) in the email on behalf of the ELI Task Force.
Thanks to Fabio for launching the discussion! John
-----Original Message----- Dear all, this mail does propose a possible organization in subcommittees of the LegalCite TC, as suggested by John at the inaugural tele-conf of this TC, but it does so at the very end of this (longish) text. I wanted first to share some preliminary
worries that are relevant to me and on which I would like to share with the rest of you.
A little background on me first: I am a computer scientist, former AC for University of Bologna at W3C, former member of some W3C committees (you can find some traces of my contributions in XML Schema, Semantic Web and XSL-FO, now part
of CSS-Pagination), and currently co-chair (with Monica Palmirani) of the LegalDocML TC in OASIS. I have some experience in handling legislation, much smaller in court documents.
Personal proposal for the definition of a few relevant terms to this TC:
* citation: an explicit, human-readable mention of a legal text as found in another text, providing sufficient detail for an averagely competent person to identify with precision the relevant text.
* reference: a machine-readable representation of a citation, containing at least the same quantity of information (but possibly more) as the plain text citation for the purpose of identifying the relevant text.
* identifier: a string univocally associated to a document that identifies it. Using an identifier in a reference is a simple way to make it work, but it is not the only way: there will be references that do not contain an identifier,
and require more work to find the relevant text. Having an explicit human readable and machine readable does not mean that they have to be fare different from each other. It is important to have a machine readable which looks as close as possible
to the human readable one. A unique identifier which should be used should be recognizable, readable and understandable by both humans and computers at the same time. Meaning that somebody who knows how to cite a legal citation in a country, will almost be able to construct the “URI” which would lead you to the machine readable citation. Next are some standard Web terms that are relevant for this TC, I believe:
* A locator is an identifier of a physical resource (e.g., a file on a hard disk somewhere on the net) that is actionable (that is, it can be immediately used for dereferencing).
* Resolution: the act of determining a usable, active locator of a physical resource given a reference to a document of which said physical resource is a reasonable representation.
* Dereferencing: the act of delivering a copy of a physical resource given its locator.
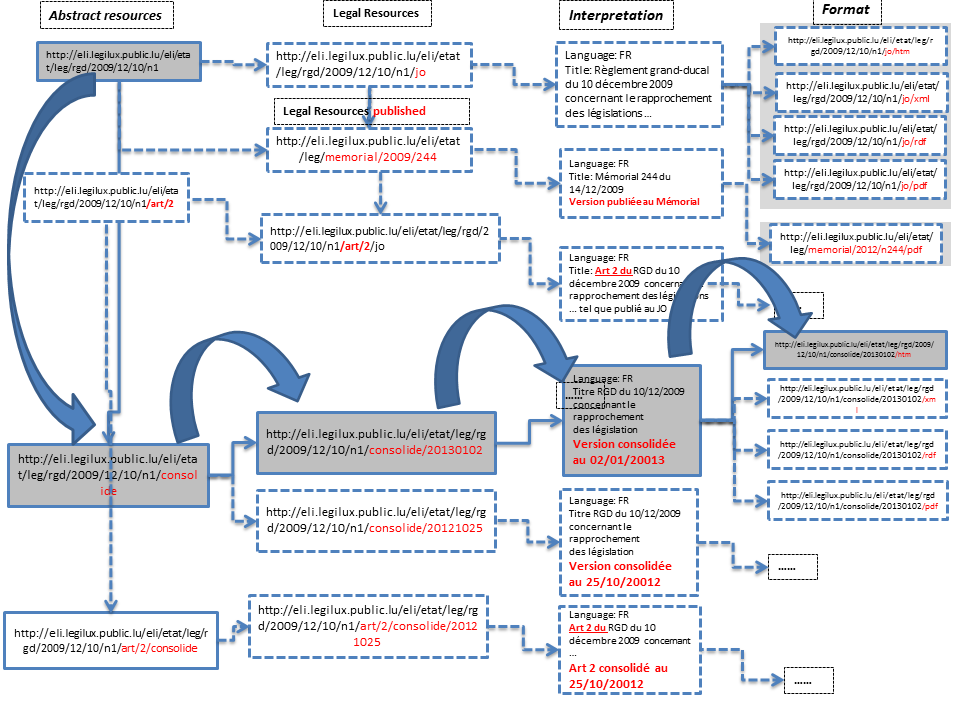
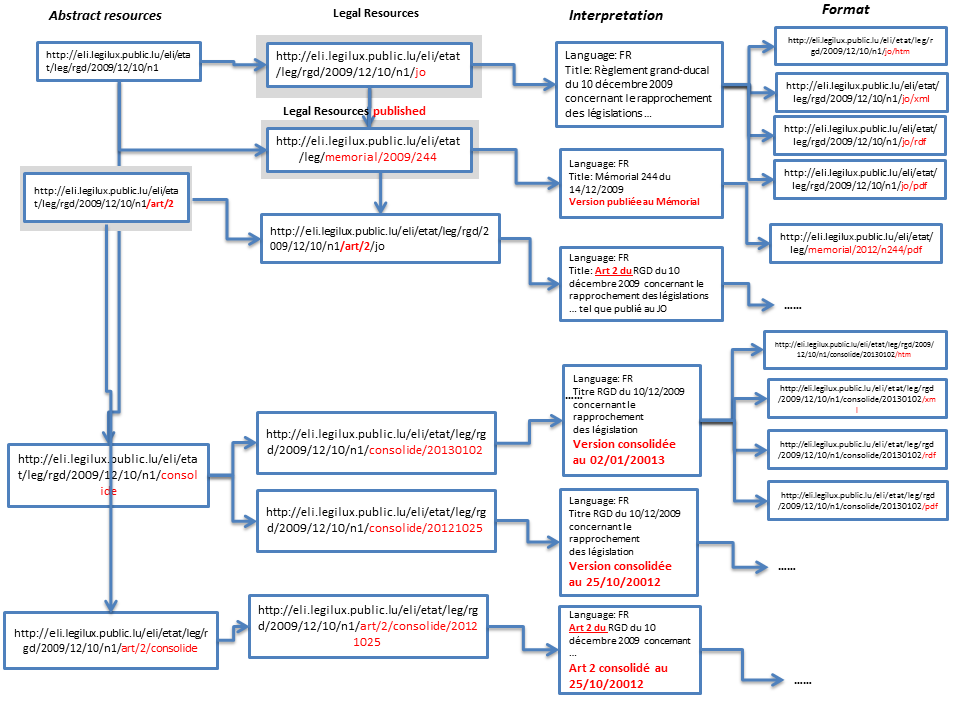
The ELI FBER model could give some ideas - abstract resource - legal resource - interpretation – format . You will notice that we have 4th layer has been added, the “abstract resource” being a new
introduction, in comparison to the FBER model – work - _expression_ –manifestation. On of the main aims of the “abstract resource” was to “link” with consolidated acts or even with other documents of other sources.
Simple example attached of the future Luxemburgish ontology.
Accessing a document given a reference, therefore, has two well-distinguished steps: the reference is first resolved, obtaining a locator, and this locator is subsequently dereferenced, obtaining a representation
of a physical copy of the document that is actually stored and available somewhere on the web.
Please note that I have abstained from using web-specific acronyms such as HTTP, URI, URL, and URN, because these concepts exist independently from their web implementation, but web standards and best practices are completely consistent
with the above terminology. The Official journals are moving away from paper versions to officially online documents, some are even moving to “Legal Open Data”. Having said that, the http URIs become more and more important
because almost all the documents are available online. Next, some basic issues that set apart legal citations from plain hypertext links on the web, in my point of view.
Most of the following reasonings derive from my experience with legislation, and I am curious to see how they fare with respect to court documents.
The most important thing that sets legal documents apart is that a citation is almost never to a physical file stored somewhere on the net. Most often it is to an abstract conceptualization of a document, that can correspond to a number
of different physical files. A few examples: * there could be many different physical copies of the same "document", some authoritative (e.g. from the web site of the office emanating it), some not so much (e.g., a union, a political party, a local administration giving access
to their own personal stash of documents even when they are not the official publishers of these documents), some plain, some richer in metadata (e.g., a commented version provided by private publisher). It is important to have an « official » source- official authority - for a legal document, which the user can trust in. This authority has, of course, also to guaranty that the provided document
is authentic, has not been altered etc. * there could be many variants of the same document differentiated by content (e.g., a full copy vs. an excerpt, maybe of a very long, multi-topical text, of the bits that are relevant to the activities of an office), by language (all
European legislation exists in 27 different languages, and the citation to an European act that an Austrian friend sends me as taken from the German version, when I use it I see the right place of the Italian version), by temporal validity (a reference to
a 1999 act subsequently modified in 2007, 2010 and 2013, if examined in 2014 for a civil suit about events in 2011, will bring me neither to the 1999 version, nor to the 2013 version, but to the 2010 version of the act).
What the public, lawyers etc. want is the OFFICIAL version * there could be citations to documents that are not accessible, available or even existing yet: e.g. a citation of a court document that will be released in a separate moment from the publication of a sentence, a citation of a document
for which I have no security clearance, a citation of a regulation that will be written after the enactment of the legislation it is mentioned in, a citation of an act that it is foreseen it will modify existence, validity or jurisdiction of this one.
Can we solve all cases ?
These cases imply, in my view, that references will always be to abstract documents, or conceptualization of documents, rather than physical files somewhere on a hard disk, and that the most appropriate physical representations of these
references will be identified at navigation time by the end user, not at the time of the creation of the reference by the author. Basically, this means that reference resolution is a NECESSARY STEP, and not an occasional aspect, of navigating legal citations.
Yes Please note that I have abstained from using librarian-specific conceptualizations such as FRBR, because these issues exist independently from their proposed solutions, but it is worth noticing that the Akoma Ntoso
naming convention, the CEN Metalex standard, the urn:lex protocol, and the ELI proposed standard all rely, explicitly or implicitly, on the concepts of FRBR.
Finally, before getting to the actual list of subcommittees, I would like to propose a first guiding principle for the activities of this working group: NO ARBITRARY STRINGS! There are two basic approaches at determining identifiers for documents: arbitrary strings or feature lists. The first relies on creating sufficiently long opaque strings and associate them to documents by fiat, so that, say, "ax45wtp987w1"
becomes the identifier of "Act n. 12 of 2013 of the Republic of Hungary"; the other is based on seeking a list of relevant characteristics of the documents, that, appropriately codified according to a given syntax, are used to identify the document, so that,
say, type=act & number=12 & year=2013 & country=hu are the features of "Act n. 12 of 2013 of the Republic of Hungary" that are necessary to identify it.
Despite arbitrary strings are easier to build tools for, I strongly urge AGAINST using them for this TC: arbitrary strings are fragile (one wrong character and you've misrepresented the reference), rely on a central marshaling station
that is the only storage of the mapping between strings and documents, shunt any guesswork on similarly named documents, etc. Arbitrary strings are evil.
If, as I hope, we go with feature lists, then an important task of this TC is to determine what are the features of proposed and enacted legislation, of sentences and related court documents, of parliamentary reports and related documents,
etc. Features should be divided in a) identifying vs. accessory (those features that are necessary to identify the document, e.g. the number of an act or the year, vs. those features that are frequently accompanying the reference, but not strictly necessary, e.g., the
month and day of an act, if the number is present and is reset at the beginning of the year) c) required vs. desired (e.g. if I request act 12/2013 in HTML, I will not accept act 13/2013 in HTML, but I am willing to accept act 12/2013 in PDF).
d) describing the cited document vs. the citation itself (e.g., the number of the act is describing the cited document, specifying that a reference is modificatory or groundwork for the judgment are justifying the citation itself, and
not describing the cited document). Thus motivation, provenance, type, purpose, scope are all features of the citation and not of the cited document.
--- Thus said, this is my proposal of subcommittees for this TC:
a) court documents: the purpose of this SC is to deliver, in a multinational, multi-language and multi-jurisdictional fashion, the features that characterize legal citations to court documents including judgments, memoirs from the parts,
trial documents, and commentaries. These features should be clearly characterized in terms of identifying vs. accessory, required vs. desired, and describing the cited document vs. describing the citation.
b) legislation: the purpose of this SC is to deliver, in a multinational, multi-language and multi-jurisdictional fashion, the features that characterize citations to proposed and enacted legislation and regulations at all levels, including
local regulations and international treaties. These features should be clearly characterized in terms of identifying vs. accessory, required vs. desired, and describing the cited document vs. describing the citation.
c) parliamentary documents: the purpose of this SC is to deliver, in a multinational, multi-language and multi-jurisdictional fashion, the features that characterize citations of parliamentary documents including hansards, orders of
the day, reports, etc. These features should be clearly characterized in terms of identifying vs. accessory, required vs. desired, and describing the cited document vs. describing the citation.
d) contracts: the purpose of this SC is to deliver, in a multinational, multi-language and multi-jurisdictional fashion, the features that characterize citations of contracts. These features should be clearly characterized in terms of
identifying vs. accessory, required vs. desired, and describing the cited document vs. describing the citation.
Not exactly what is meant by contracts – contracts between two businesses e.g. – if yes not sure this would be the place. e) technical SC: the purpose of this SC is to deliver one or more syntactical approaches to express the features of the above-mentioned citation types, so as to provide an easily implementable navigation system using standard browsing
tool, as well as to determine behavior, response types and error handling of tools connected to the use of legal references, mainly how to characterize successful and unsuccessful resolution and dereferencing of legal references.
Concerning a b c, I am not convinced that we need 3 sub-committees for each purpose. Legal documents are still quite similar, even if they come out of courts, the parliament or governments. If we want this identifier to work around the world, it is very important that this identifier or system is compatible with existing technological systems. Nobody will change completely their system
to implement a new standard, but they will be willing to adapt slightly or add a layer to their existing systems.
A flexible, self-documenting, consistent and unique way to reference legislation across different legal systems is a need. But the magic word is flexible, because of the so many different legal systems
in the world.. A flexible identifier would be a set of building blocks where each country, region …, courts, parliaments etc … can take the bricks they need to uniquely identify their documents. There is no need
to have a identical identifier everywhere, which by the way would be impossible.
Everybody takes its pieces of LEGO (child memories) and will build its own identifier, but on a common and big (flexible) ground In case you are still awake after all this, let me know your opinions.
Ciao Fabio Vitali -- Fabio Vitali Tiger got to hunt, bird got to fly, Dept. of Computer Science Man got to sit and wonder "Why, why, why?' Univ. of Bologna ITALY Tiger got to sleep, bird got to land, phone: +39 051 2094872 Man got to tell himself he understand. e-mail: fabio@cs.unibo.it Kurt Vonnegut (1922-2007), "Cat's cradle" http://vitali.web.cs.unibo.it/ --------------------------------------------------------------------- To unsubscribe from this mail list, you must leave the OASIS TC that generates this mail. Follow this link to all your TCs in OASIS at: https://www.oasis-open.org/apps/org/workgroup/portal/my_workgroups.php
|
Attachment:
pngMxEDmkS6LK.png
Description: =?iso-8859-1?Q?ELI=5FStructure=5FLuxembourg_decembre_2013_fl=E8che.png?=
Attachment:
ELI_Structure_Luxembourg decembre 2013.png
Description: ELI_Structure_Luxembourg decembre 2013.png
Attachment:
ELI-Structure.PNG
Description: ELI-Structure.PNG
[Date Prev] | [Thread Prev] | [Thread Next] | [Date Next] -- [Date Index] | [Thread Index] | [List Home]
{kind=link}
{kind=link}
{kind=link}