[Date Prev] | [Thread Prev] | [Thread Next] | [Date Next] -- [Date Index] | [Thread Index] | [List Home]
Subject: RE: [xliff] Event "XLIFF TC Call" - Summary
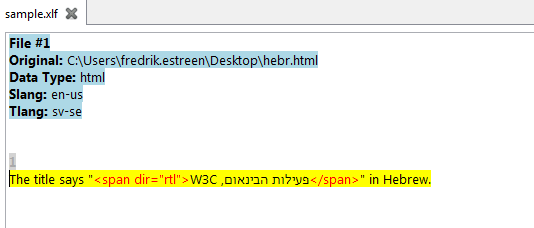
Hi Yves and Rodolfo, We (Lionbridge) currently determine the paragraph base directions from the languages used for source and target and do not store the directionality information in the Xliff document. During translation the translator may insert Unicode directional markers or override characters to force a specific direction for neutral characters or embedded spans, this is sometimes necessary around product names and such. We store all such characters and markers as their Unicode code points in the Xliff document. We then use the normal Unicode rendering algorithm to display the result. In our tools we also use Unicode directional control characters to produce proper rendering of inline tags in RTL material. But these are not stored in the Xliff document and is an internal property in our tools only. The responsibility to insert necessary directional overrides in cases like the embedded Hebrew would be on the application converting the source document to Xliff. I attached a screenshot of our rendering and two samples of essentially the same Xliff, one using numeric entities instead of direct characters to make it more visible. But we will need control information in one way or the other to handle these cases correctly when displaying in an editor. Unfortunately our extractor does not currently add the control codes properly for HTML so my sample xliffs are "fixed" by adding the codes. The discussion around BiDi marker tags in the inline content comes from the recommendation of other XML standards to use this approach instead of Unicode control characters. I personally prefer using the Unicode rendering algorithm and store the Unicode code-points/characters controlling directionality directly. The reason to use a tag or attribute instead is mainly to get better visual appearance of the XML document in a simple text editor. Inspecting and editing an XML document with right to left content and control characters in a simple text editors is not fun. But I doubt the view is significantly better if the content still contains RTL characters and just the control characters are put as tags. The idea about a document level attribute probably need more discussion to see if there is any use case that is not covered by using the directions of the languages as the base directions. One possible use case I can think of right now would be Chinese text on vehicles. There we have a base direction of left-to-right for the language, but the direction is actually determined by what side of the vehicle the text is displayed on (text starts at the front and continues towards the back). One more East Asian case is the top-down directionality of some texts. See http://en.wikipedia.org/wiki/Horizontal_and_vertical_writing_in_East_Asian_scripts for more examples. I do agree that these use cases are very limited and may not warrant a new attribute in Xliff. Regards, Fredrik Estreen -----Original Message----- From: xliff@lists.oasis-open.org [mailto:xliff@lists.oasis-open.org] On Behalf Of Rodolfo M. Raya Sent: den 19 oktober 2011 14:21 To: xliff@lists.oasis-open.org Subject: RE: [xliff] Event "XLIFF TC Call" - Summary Hi Yves, In Swordfish your sample text is extracted like this: <source xml:lang="en">The title says "<ph id="0" ctype="x-other"><span dir="rtl"></ph>פעילות הבינאום, W3C<ph id="1"></span></ph>" in Hebrew.</source> Regards, Rodolfo -- Rodolfo M. Raya rmraya@maxprograms.com Maxprograms http://www.maxprograms.com -----Original Message----- From: xliff@lists.oasis-open.org [mailto:xliff@lists.oasis-open.org] On Behalf Of Yves Savourel Sent: Wednesday, October 19, 2011 9:55 AM To: xliff@lists.oasis-open.org Subject: RE: [xliff] Event "XLIFF TC Call" - Summary Hi Rodolfo, > Swordfish analyzes the text to translate and renders it using the BiDi > algorithm from Unicode. The program doesn't need a hint from the XLIFF > markup to render mixed text. So Swordfish uses Unicode bidi characters control for hints (like Trados and Lionbridge's editors). Sounds fine to me. One follow up questions then (and not just for Rodolfo): When extracting a text like this: <p>The title says "<span dir="rtl">פעילות הבינאום, W3C</span>" in Hebrew.</p> Where the "W3C, " part should be on the left side of the quoted text when editing/rendering properly. As shown in the screenshot attached. How does Swordfish (or other tools) stores the original HTML codes and markup the text? Do they store the <span> as like any other elements and just add U+202B and U+202C to the text? Something like this: <source> The title says "<g id="1">[U+202B]פעילות הבינאום, W3C[U+202C]</g>" in Hebrew.</span> Cheers, -ys --------------------------------------------------------------------- To unsubscribe, e-mail: xliff-unsubscribe@lists.oasis-open.org For additional commands, e-mail: xliff-help@lists.oasis-open.org
Attachment:
sample.xlf
Description: sample.xlf
Attachment:
sample-ent.xlf
Description: sample-ent.xlf
Attachment:
rtl-embedd.png
Description: rtl-embedd.png
[Date Prev] | [Thread Prev] | [Thread Next] | [Date Next] -- [Date Index] | [Thread Index] | [List Home]
{kind=link}